Mnih, Kavukcuoglu, Silver, Graves, Antonoglon, Wierstra, and Riedmiller authored the paper “Playing Atari with Deep Reinforcement Learning” which describes and an Atari game playing program created by the company Deep Mind (recently acquired by Google). The AI did not just learn how to pay one game. It learned to play seven Atari games without game specific direction from the programmers. (The same learning parameters, neural network topologies, and algorithms were used for every game).
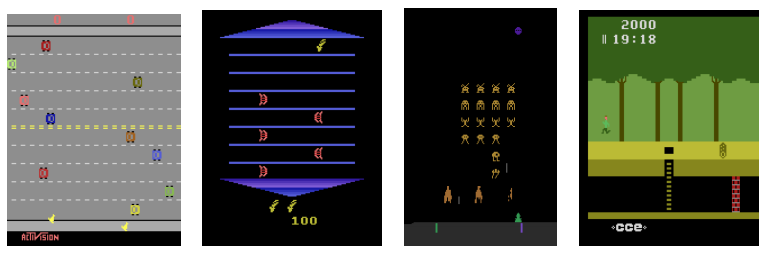
The 2600 Atari gaming system was quite popular in the late 1970’s and the early 1980’s. The games ran with only four kilobytes of RAM and a 210 x 160 pixel display with 128 colors. Various machine learning techniques have been applied to the old Atari games using the Arcade Learning Environment which precisely reproduces the Atari 2600 gaming system. (See e.g. “An Object-Oriented Representation for Efficient Reinforcement Learning” by Diuk, Cohen, and Littman 2008, ”HyperNEAT-GGP:A HyperNEAT-based Atari General Game Player” by Hausknecht, Khandelwal, Miikkulainen, and Stone 2012, “Application of TEXPLORE on Atari Games “ by Shung Zhang , ”A Neuroevolution Approach to General Atari Game Playing” by Hausknect, Lehman,” Miikkulalianen, and Stone 2014, and “Replicating the Paper ‘Playing Atari with Deep Reinforcement Learning’ ” by Korjus, Kuzovkin, Tampuu, and Pungas 2014.)
Various papers have been written on how computers can learn to pay the Atari games, but most of them used the abstract representations of objects on the screen within the emulator. The Mnih et al AI learned to play the games using only the raw 210 x 160 video and the score. It seems to be the first successful attempt to learn arcade gaming from raw video.
To learn from raw video, they first converted the video to grayscale and then downsampled/cropped to 84 x 84 images. The last four frames were used to determine actions. The 28224 input pixels were run through two hidden convolution neural net layers and one fully connected (no convolution) 256 node hidden layer with a single output for each possible action. Training was done with stochastic gradient decent using random samples drawn from a historical database of previous games played by the AI to improve convergence (This technique known as “experience replay” is described in “Reinforcement learning for robots using neural nets” Long-Ji Lin 1993.)
The objective function for supervised learning is usually a loss function representing the difference between the predicted label and the actual label. For these games the correct action is unknown, so reinforcement learning is used instead of supervised learning. The authors used a variant of Q-learning to train the weights in their neural network. They describe their algorithm in detail and compare it to several historical reinforcement algorithms, so this section of the paper can be used as a brief introduction to reinforcement learning.
The AI was trained to play seven games: Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, and Space Invaders. In six of the seven games, this general game learning algorithm outperformed all previously known reinforcement learning algorithms tested on those games and “surpasses a human expert on three” of the seven games.