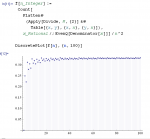
So I decided to look at other AI blogs and I began by typing “artificial intelligence blog” into Google. (That might not be the best way to find AI blogs, but it seemed like a good place to start.) Most of the links were popular blogs with an article on AI (like the Economist commenting on crossword AI). Here are some of the other links I came across:
A Great List of AI resources
http://www.airesources.info/
Blog – Lisp – 3 posts this year
http://p-cos.blogspot.com/
IEEE on AI
http://spectrum.ieee.org/robotics/artificial-intelligence/
AliceBot
http://alicebot.blogspot.com/
Robotics
http://www.robotcompanions.eu/blog/
Two posts this year – One of the posts is very good.
http://artificialintelligence-notes.blogspot.com/
Good ML blog
http://hunch.net/
This blog markets “Drools” software.
http://blog.athico.com/
Great response to a question about resources for AI.
http://stackoverflow.com/questions/821204/best-books-blogs-link-reading-about-ai-and-machine-learning
Social Cognition and AI
http://artificial-socialcognition.blogspot.com/
AI applied to the stock market
http://thekairosaiproject.blogspot.com/